# AI Safety Guardrails
## ⚡We *Care*. Period.
{% content-ref url="../../../platform+/active-development/human-in-the-loop" %}
[human-in-the-loop](https://docs.lisaiceland.com/platform+/active-development/human-in-the-loop)
{% endcontent-ref %}
{% content-ref url="../../../platform+/active-development/advanced-agent-verifier" %}
[advanced-agent-verifier](https://docs.lisaiceland.com/platform+/active-development/advanced-agent-verifier)
{% endcontent-ref %}
{% content-ref url="ai-safety-guardrails" %}
[ai-safety-guardrails](https://docs.lisaiceland.com/smarter-ai-learn-more/ai-safety+/guardrails+/ai-safety-guardrails)
{% endcontent-ref %}
{% content-ref url="../../../platform+/active-development/testing" %}
[testing](https://docs.lisaiceland.com/platform+/active-development/testing)
{% endcontent-ref %}

Last updated: March 24, 2026.
[](https://camo.githubusercontent.com/26641b5a70dea0526ad84e92b8d1dea013f3682c187ef1cac1ac09685e2c31e2/68747470733a2f2f696d672e736869656c64732e696f2f62616467652f74657374732d39373725323070617373696e672d627269676874677265656e) [](https://camo.githubusercontent.com/75fde65290dbfc7dd2b52c4aa25a9f069d8f342dd65f96e40ddf31bab03b69bc/68747470733a2f2f696d672e736869656c64732e696f2f62616467652f746573746564253230776974682d7669746573742d364539463138) [](https://camo.githubusercontent.com/526cf55b8be703ab2d413b92d1ccf65a837f02413ed34f9f3015fc0e07161bf8/68747470733a2f2f696d672e736869656c64732e696f2f62616467652f6c616e6775616765732d33372d626c7565) [](https://camo.githubusercontent.com/991e44d30e63e00f5d26eb53658c85234ebfbfad6a72f2854fddb9ebd5ba80d3/68747470733a2f2f696d672e736869656c64732e696f2f62616467652f42594f4b25323070726f7669646572732d31382d6f72616e6765) [](https://camo.githubusercontent.com/9848248df8f878d8a375f7a0993b27219c2ed5c209d9a2442e6001064201a7cc/68747470733a2f2f696d672e736869656c64732e696f2f62616467652f73656375726974792d68617264656e65642d637269746963616c)
 [](https://camo.githubusercontent.com/c6d47a185d7feee3e89913188f3f3f27c0dcd3c37348c167e7c76818d565e5d4/68747470733a2f2f696d672e736869656c64732e696f2f62616467652f7368697070656425323066656174757265732d7e3332352d677265656e)
***
## AI Voice+
### Overview
AIVoice+ implements a layered guardrails system across all AI-powered features. These guardrails protect the superadmin, the company, and paying users without sacrificing speed or UX.
***
### Layered Guardrails Stack
#### 1. Policy Layer (System Prompt)
* `SAFETY_PREAMBLE` injected into every AI conversation
* Non-negotiable rules that the model must follow
* Covers: role adherence, content restrictions, data handling
#### 2. Capability Layer (Input Validation)
* Message length limits (10,000 characters)
* UUID format validation for workspace/run IDs
* Input type checking (string, required fields)
#### 3. Intent Layer (Injection Scanning)
* 10 regex patterns detecting prompt injection attempts
* Safe-wrapping of detected injections (not blocking — preserves UX)
* Audit logging of all injection detections
#### 4. Runtime Layer (Rate Limiting & Quotas)
* IP-based rate limiting: 30 messages / 15 minutes per endpoint
* Per-org daily quotas: 100 messages/day (configurable per plan)
* Fail-closed rate limiter: if the DB is down, requests are blocked (not allowed)
#### 5. Tool Layer (MCP & Agent Sandboxing)
* Per-request context isolation in MCP server (no global state)
* Org-scoped queries in all tool handlers
* API key hashing (SHA-256) for MCP authentication
***
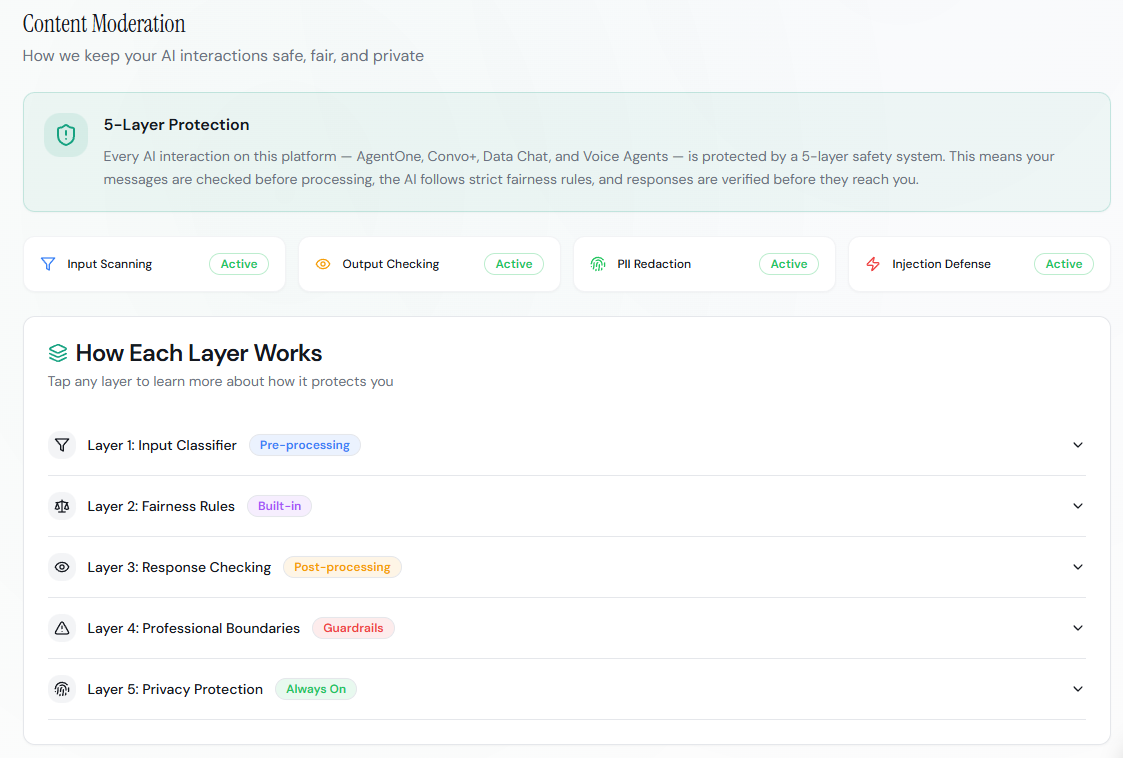
### 9 Guardrail Categories
| # | Category | Implementation |
| - | --------------------------- | ------------------------------------------------------------- |
| 1 | **Safety** | Content moderation via AI gateway (fail-closed) |
| 2 | **Professional Boundaries** | No medical/legal/financial advice in system prompt |
| 3 | **Hallucination** | Uncertainty disclosure instructions in preamble |
| 4 | **Bias** | Equitable treatment instructions (see BiasProtections.md) |
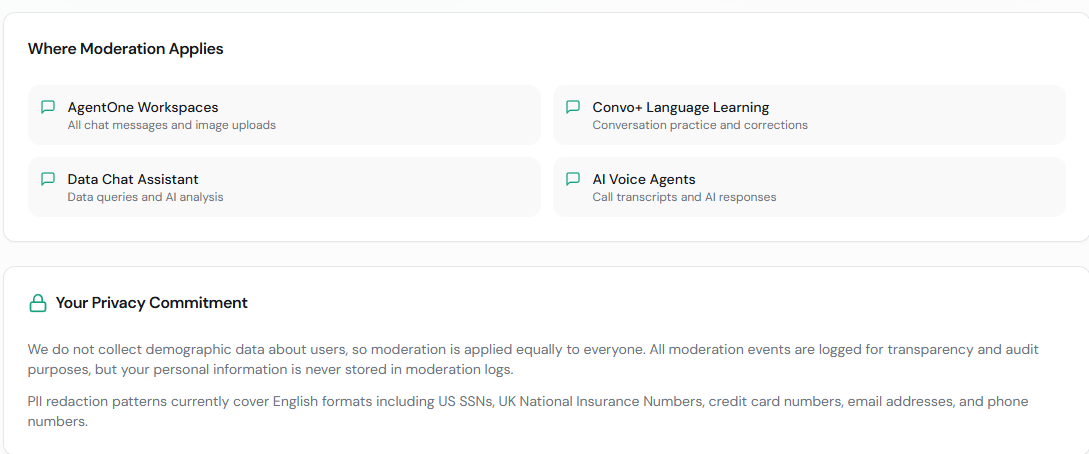
| 5 | **Privacy** | PII redaction (5 patterns), data minimization |
| 6 | **Manipulation** | Blocked voice phrases, injection detection |
| 7 | **Refusal** | Graceful decline for unsafe/out-of-scope requests |
| 8 | **Autonomy** | Self-restricting agent instructions ("ask for clarification") |
| 9 | **Evaluation** | Audit logging to `ai_usage_logs` for all safety events |
***
### Agent Safety Modes
All AI agents operate in a single safety mode: **Standard**. This mode applies all guardrails uniformly. There is no "relaxed" or "unrestricted" mode.
***
### Voice-Specific Guardrails
#### Blocked Voice Phrases
The following phrases are flagged in voice output scanning:
* "guaranteed results"
* "trust me"
* "no risk"
* "100% safe"
* "you must"
* "i promise"
These are scanned client-side via `scanBlockedVoicePhrases()` in `agent-one-safety.ts`.
***
### Error Masking Policy
All edge functions return generic error messages to clients:
* **Client sees**: `"An unexpected error occurred"`
* **Server logs**: Full error details via `console.error()`
This prevents information leakage about internal architecture, database structure, or API configurations.
**Affected functions**: `delete-organization`, `store-checkout`, `send-email`, `create-vapi-assistant`, `snapshot-org-stats`, `admin-ai-insights`, `ai-contact-reply`, `chat-with-data`
***
### Logging & Audit Trail
| Event | Feature Tag | Table |
| --------------------------------- | -------------------------------------------------------------------------------------- | ------------------ |
| Content moderation block (input) | `agent_one_moderation_block` / `convo_moderation_block` / `chat_data_moderation_block` | `ai_usage_logs` |
| Content moderation block (output) | `convo_output_moderation_block` | `ai_usage_logs` |
| Injection detection | `injection_detected` | `ai_usage_logs` |
| Normal AI usage | `agent_one_chat` / `convo_chat` / `chat_with_data` | `ai_usage_logs` |
| Rate limit hits | IP + endpoint logged | `auth_rate_limits` |
***
### Framework Alignment
This guardrails implementation aligns with:
* **NIST AI RMF**: Map → Measure → Manage → Govern cycle. Our guardrails cover the Manage function (risk mitigation controls).
* **EU AI Act**: Our AI systems would be classified as "limited risk" (chatbots). We implement transparency (safety notices) and human oversight (content moderation).
* **ISO/IEC 42001**: Our safety pipeline documents align with the AI management system requirements.
These are reference alignments, not certifications. External auditing is recommended for formal compliance.
***
### What We Intentionally Do NOT Implement
| Item | Reason |
| ---------------------- | -------------------------------------------------------- |
| CORS restriction | Would break MCP clients and external integrations |
| Differential privacy | Academic technique, not applicable to chat-based SaaS |
| Model retraining | We use third-party models; we mitigate via prompts |
| Real-time bias scoring | Would add latency; we use post-hoc audit logging instead |
### Content Moderation (how it's done on our platform)
{% content-ref url="../../../privacy+/content-moderation" %}
[content-moderation](https://docs.lisaiceland.com/privacy+/content-moderation)
{% endcontent-ref %}